Акушерство и Гинекология №2 / 2024
Сравнение прогностических моделей, построенных с помощью разных методов машинного обучения, на примере прогнозирования результатов лечения бесплодия методом вспомогательных репродуктивных технологий
ФГБУ «Национальный медицинский исследовательский центр акушерства, гинекологии и перинатологии имени академика В.И. Кулакова» Минздрава России, Москва, Россия
В репродуктивной медицине развитие машинного обучения (МО) привело к созданию большого количества вспомогательных программных продуктов. Прогнозирование результативности программы вспомогательных репродуктивных технологий (ВРТ) при помощи МО может быть осуществлено с использованием различных алгоритмов в зависимости от типа данных и поставленной задачи.
Цель: Сравнение прогностической способности логистической регрессии, алгоритма решающего дерева и Random Forest в отношении вероятности наступления беременности на основании клинико-анамнестических и эмбриологических данных пациентов в программе ВРТ.
Материалы и методы: В ретроспективное исследование были включены 854 супружеские пары. В исследовании были проанализированы клинико-лабораторные данные и параметры стимулированного цикла в зависимости от результативности программы ВРТ при помощи трех алгоритмов МО: логистической регрессии, решающего дерева и Random Forest.
Результаты: Наиболее точным алгоритмом прогнозирования частоты наступления беременности в программе ВРТ стала модель на основе Random Forest, которая определила значимость следующих предикторов: остановка эмбрионов в развитии, триггер финального созревания ооцитов, количество эмбрионов отличного и среднего качества, продолжительность стимуляции, фактор бесплодия, индекс массы тела, уровни ФСГ и АМГ; а также подтвердила значимость предикторов, которые были определены на предыдущих этапах работы, при помощи алгоритма решающего дерева: наличие/отсутствие беременностей в анамнезе, параметры стимулированного цикла (число ооцитов MII), показатели спермограммы в день пункции, количество эмбрионов отличного и хорошего качества, а также качество эмбриона согласно морфологическим критериям оценки.
Заключение: Для улучшения прогнозирования эффективности программы ВРТ требуются более качественные математические модели с интегральным подходом к решению задачи с использованием большой выборки пациентов с различными входными данными, представленными в сбалансированном объеме, а также дополнительные маркеры, определяющие эффективность программы ВРТ, позволяющие улучшить точность программного продукта.
Вклад авторов: Драпкина Ю.С., Макарова Н.П., Калинина Е.А. – концепция и дизайн исследования; Драпкина Ю.С. – сбор и обработка материала; Амелин В.В., Васильев Р.А. – статистическая обработка данных; Драпкина Ю.С., Амелин В.В., Васильев Р.А. – написание текста статьи; Калинина Е.А., Макарова Н.П. – редактирование.
Конфликт интересов: Авторы заявляют об отсутствии возможных конфликтов интересов.
Финансирование: Работа проведена без привлечения дополнительного финансирования со стороны третьих лиц.
Одобрение Этического комитета: Исследование было одобрено локальным Этическим комитетом ФГБУ «НМИЦ АГП им. академика В.И. Кулакова» Минздрава России.
Согласие пациентов на публикацию: Пациенты подписали информированное согласие на публикацию своих данных.
Обмен исследовательскими данными: Данные, подтверждающие выводы этого исследования, доступны по запросу у автора, ответственного за переписку, после одобрения ведущим исследователем.
Для цитирования: Драпкина Ю.С., Макарова Н.П., Васильев Р.А., Амелин В.В., Калинина Е.А. Сравнение прогностических моделей, построенных с помощью разных методов машинного обучения, на примере прогнозирования результатов лечения бесплодия методом вспомогательных репродуктивных технологий.
Акушерство и гинекология. 2024; 2: 97-105
https://dx.doi.org/10.18565/aig.2023.263
Развитие системы здравоохранения в России зависит от использования современных технологий. Все большее внимание уделяется применению различных математических алгоритмов для повышения качества медицинской помощи [1, 2]. Одним из направлений применения искусственного интеллекта (ИИ) является машинное обучение (МО). Основная задача МО заключается в создании алгоритмов, которые могут принимать входные данные и использовать их для прогнозирования выходной информации по мере появления новых данных. Стоит отметить, что МО представляет собой не только статистические методы, и в основе МО лежит построение алгоритмов, основанных на обучении, без явной формы решения [3].
МО широко применяется в различных сферах медицины, в том числе внедряется и в области вспомогательных репродуктивных технологий (ВРТ). В репродуктивной медицине развитие МО привело к созданию большого количества вспомогательных программных продуктов [4]. В настоящий момент внимание ученых привлекает разработка программ для прогнозирования эффективности ВРТ, а также выбора и оптимизации метода лечения [5].
Стоит отметить, что ошибочное и неточное прогнозирование исхода программы ВРТ не позволяет своевременно ориентировать супружескую пару на использование того или иного метода лечения и корректировать ожидания пациентов в отношении частоты наступления беременности, а также препятствует целесообразному клинико-экономическому распределению средств Фонда обязательного медицинского страхования (ОМС) [6]. В связи с этим при разработке программного продукта задача прогнозирования эффективности программы ВРТ становится наиболее приоритетной.
Прогнозирование результативности программы ВРТ при помощи МО может быть осуществлено с использованием различных алгоритмов в зависимости от типа данных и поставленной задачи. Среди основных методов МО, используемых в репродуктивной медицине, выделяют логистическую регрессию, алгоритм решающего дерева, метод случайного леса (Random Forest) [7].
Логистическая регрессия
Логистическая регрессия решает задачу классификации, показывая вероятность того, что данное исходное значение принадлежит к определенному классу. Если точки исходных данных удовлетворяют этому требованию, то их можно назвать линейно разделяемыми [8] (рис. 1).
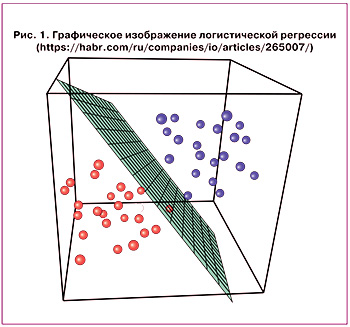
При этом, чем дальше находится точка от разделяющей поверхности, тем выше шансы, что она принадлежит к данному классу.
Алгоритм решающего дерева
Алгоритм решающего дерева разделяет набор данных на меньшие подмножества в зависимости от их характеристик. Суть метода заключается в том, что дерево решений многократно разделяет данные, пока не останется только один класс. При построении дерева решений используется критерий Джини (Gini impurity) [9].
При выборе разделения узла по определенному признаку, критерий Джини отражает, насколько это разделение снижает неопределенность в данных [10].
Алгоритм случайного леса (Random Forest)
Стоит отметить, что одно решающее дерево имеет тенденцию к переобучению под конкретную обучающую выборку, поэтому на практике следует использовать композицию решающих деревьев (Random Forest). В основе алгоритма Random Forest лежит использование нескольких решающих деревьев. Они показывают логику, благодаря которой исследователь принимает решения. Оптимизация решающих деревьев под конкретную задачу сводится к перебору признаков и порогов разбиения, чтобы найти лучшее разбиение. Дерево сильно меняется при изменении выборки, поэтому для построения разнообразных деревьев из выборки длиной M выбираются подмножества такой же длины M с возвращением, и на этих подмножествах строятся деревья. Такой подход называется bootstrap. В задаче регрессии результаты, полученные «множеством» деревьев, усредняются, в задаче классификации – принимается решение голосованием по большинству. Также при построении дерева можно перебирать не все признаки, а выбирать из некоторого случайного подмножества q. Деревья можно строить параллельно, так как построения не зависят друг от друга [11].
В настоящий момент опубликовано большое количество работ, посвященных разработке предиктивной модели исхода программы ВРТ на основе МО; однако исследования, посвященные сравнению разных алгоритмов МО и изучению работы каждой модели в зависимости от полученных результатов, представлены в современной литературе в ограниченном объеме в связи с техническими ограничениями, такими как трудности в определении причинно-следственных связей между данными, полученными в ходе МО, необходимости использования большого массива данных, построении модели с использованием различных алгоритмов и т.д.
Целью данной работы явилось сравнение прогностической способности логистической регрессии, алгоритма решающего дерева и Random Forest в отношении частоты наступления беременности на основании клинико-анамнестических и эмбриологических данных когорты пациентов при лечении бесплодия методами ВРТ.
Материалы и методы
Совместно со специалистами в области МО и ИИ на первом э...












